A8体育直播官网 天下初次单机纳降万亿巨模DeepSeek-V4! RL后锻真金不怕火框架Orbit开源!


从数学、代码、复杂推理,到多轮器具调用,大模子的许多才气的晋升都离不开 RL 后锻真金不怕火。但当模子限制参加 MoE 万亿参数级别之后,RL 不再仅仅一个算法问题,同期愈加是一个系统问题。
锻真金不怕火侧需要容纳庞大的模子权重、梯度和优化器景况;rollout 侧需要握续生成样本,并保握鼓胀高的费解;reference policy 又会进一步放大显存和诊治压力。同期,许多 RL 系统在锻真金不怕火时使用较高精度模子,而确实 rollout 或部署时使用低精度 serving 模子。这些精度各异,最终会体当今部署着力与 RL 着力的不一致上。
通过将 base model 固定在部署时使用的低精度暗示,并只更新 adapter,Orbit 将 Kimi-K2.6、DeepSeek V4 级别的 1T 模子 RL 后锻真金不怕火压缩到单台 8×B200 上完成。同期,锻真金不怕火和 rollout 使用肃清条低精度 base + adapter 旅途,从系统层面摈斥了锻真金不怕火模子与 rollout / 部署模子之间的精度不一致。
Orbit 作念到「让万亿模子参加单节点 RL 区间」这件事的意旨在于:
幸免了「锻真金不怕火精度」和「部署精度」不一致带来的偏差,从而带来更褂讪更高效的 RL 后锻真金不怕火;
单节点 RL 不错显赫缩短多节点锻真金不怕火时的通讯时延与故障率;
在相同的 HBM 预算下,模子会取得更宽的锻真金不怕火空间,以前需要多卡才能训的模子,有契机被压缩到单卡。

官方博客:https://spherelab.ai/orbit/
Github:https://github.com/Sphere-AI-Lab/orbit
Orbit:解救万亿参数模子 RL 微调的高效框架
显存规章:如下图 1 所示的估算中,单节点 8×B200 的 HBM 预算约为 1536GB。对 1T 级模子而言,传统全参微调的 weight + grad 显存下界会远超单机预算;而 Orbit 旅途由于冻结低精度 base,只锻真金不怕火 adapter,不错把 1T 级模子的 RL 后锻真金不怕火放进单节点预算内。
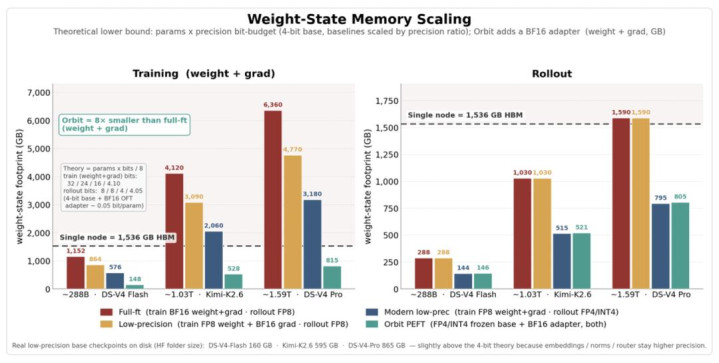
图 1 不同框架下大参数模子的单节点显存需求估算
训推精度对皆:在许多 RL 系统里,锻真金不怕火侧可能使用 BF16 或 FP8 等高精度 ,而推理侧使用 INT4、FP4 等低精度。关于监督微调来说,这种各异有时不错被视作推理优化的一部分;但在 RL 中,policy log-prob 本人即是锻真金不怕火信号的一部分,锻真金不怕火侧和推理侧之间的过错 log-prob diff 会平直影响褂讪性。
Orbit 将这一问题前置到了系统筹算中:锻真金不怕火和推理使用相易的低精度 base ,并在其上加载肃清个 BF16 adapter,从而保握训推精度一致。
Adapter-first 的系统筹算:Orbit 围绕 adapter 对 RL 锻真金不怕火、推理、同步、reference policy 和低精度 MoE 作念了一套举座筹算。base 永恒冻结,每次锻真金不怕火更新后,只需要将 MB 级 adapter (不需将 GB 级的 base)从锻真金不怕火引擎推送到推理引擎。这不仅减少了权重同步的体积,也幸免了频长途建推理引擎的支出。
单节点 Kimi-K2.6 驱散
在这组实验中,模子运转在单台 8×B200 上,锻真金不怕火精度为 INT4 base + BF16 adapter,rollout 精度使用相易的 INT4 base + BF16 adapter。也即是说,锻真金不怕火和 rollout 走的是肃清条低精度 base + adapter 旅途。
在约 200 step 的 RL 经由中,Orbit 不雅察到了几个同期修复的信号:
reward 飞腾;
eval accuracy 飞腾;
pass@k 飞腾;
train-rollout log-prob diff 保握褂讪。
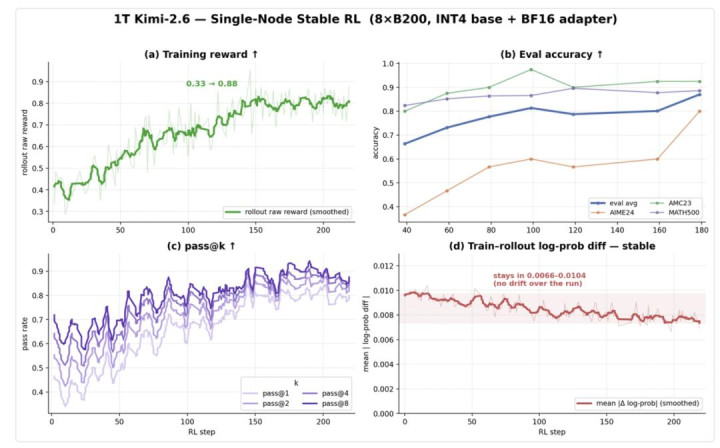
图 2 Kimi-2.6 在 Orbit 下单机 RL 后锻真金不怕火信号
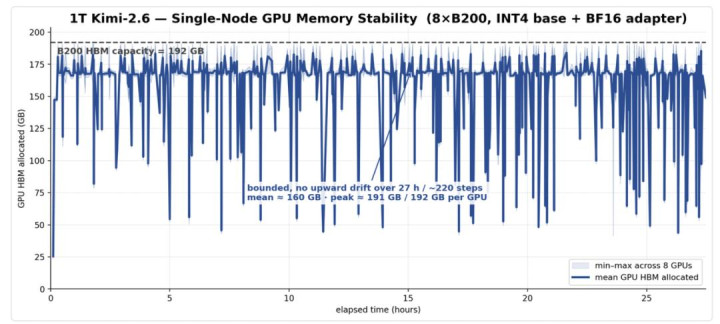
图 3 Kimi-2.6 在 Orbit 下单机 RL 后锻真金不怕火的显存记载
图 2 浮现,Kimi-K2.6 的 rollout raw reward、eval accuracy 和 pass@k 弧线随锻真金不怕火鼓舞而褂讪飞腾。同期,train-rollout log-prob diff 褂讪保管在一个区间。
关于一个对 log-prob 各异相配明锐的锻真金不怕火范式来说,A8体育直播官网这些信号实质量讲解了 Orbit 的 RL 后锻真金不怕火闭环不仅在单机上把 1T 的模子上褂讪能跑,同期跑对了且在测试任务上灵验率。
单节点 DeepSeek V4 Flash 驱散
在这组实验中,DeepSeek V4 Flash 相同运转在单台 8×B200 上。锻真金不怕火精度为 FP4 base + BF16 adapter,rollout 精度也使用相易的 FP4 base + BF16 adapter。
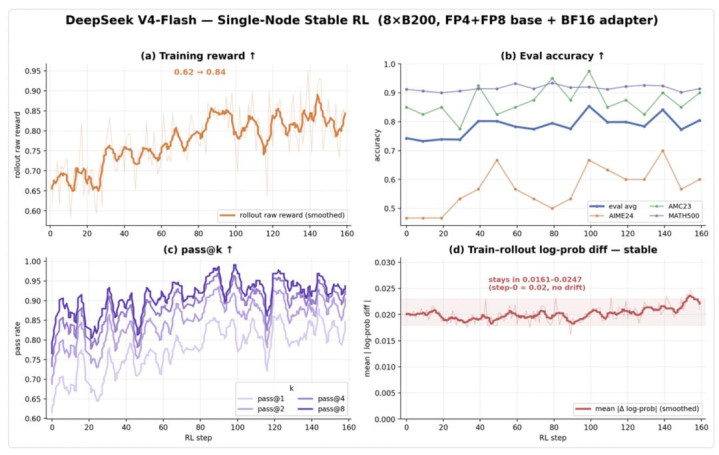
图 4 DeepSeek V4 Flash 在 Orbit 下单机 RL 后锻真金不怕火信号
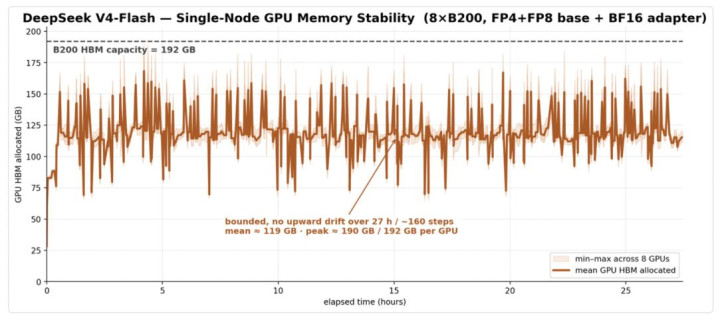
图 5 DeepSeek V4 Flash 在 Orbit 下单机 RL 后锻真金不怕火的显存记载
从驱散看,DeepSeek V4 Flash 在 100 step 以上的 RL 经由中相同保握褂讪:reward、eval、pass@k 举座飞腾,train-rollout log-prob diff 保握在褂讪区间。这些趋势跟在 Kimi-K2.6 上的实验驱散雷同。
单节点 1.6T DeepSeek V4 Pro 初步考证
除了 Kimi-K2.6 和 DeepSeek V4 Flash 两组褂讪灵验的锻真金不怕火驱散,Orbit 还在 DeepSeek V4 Pro 1.6T 上完成初步考证。
由于 DeepSeek V4 Pro base model 本人很强,实验顶用的 RL 锻真金不怕火数据不可让它涨点,因此该实验更多是讲解 Orbit 的系统旅途不错彭胀到更大的 1.6T 级 MoE 模子。
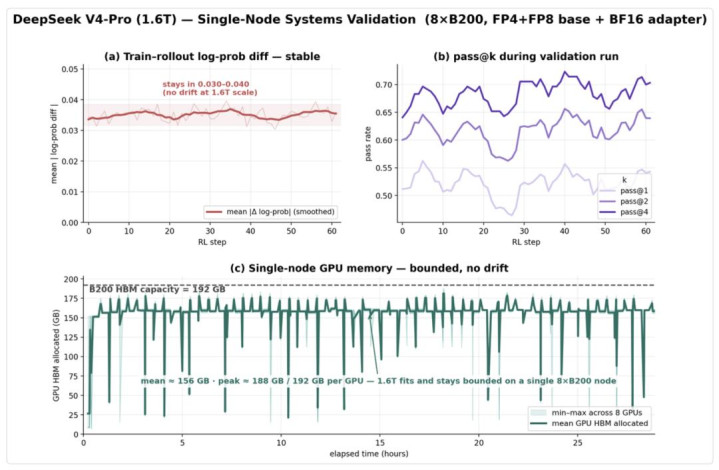
图 6 DeepSeek V4 Pro 在 Orbit 下单机 RL 后锻真金不怕火信号和显存记载
在 1.6T DeepSeek V4 Pro 上,Orbit 完成了单节点 8×B200 的实验,展示了褂讪的 train-rollout log-prob diff 和可控褂讪的 GPU 显存。
这组驱散讲解 Orbit 的系统上限可在单节点 8×B200 达到 1.6T 级别,展示了其筹算有契机隐蔽更大的 MoE 模子区间。
从单节点万亿模子,到单卡更大模子
开云体育官方网站 - KAIYUN单节点跑通万亿模子 RL 反过来也领略了相同的硬件预算就不错隐蔽更大的模子区间。
对万亿模子来说,这意味着原来可能需要多机协同的 RL 后锻真金不怕火,不错被压缩到单节点完成。对中小模子来说在 Orbit 的 adapter-first 框架下,单卡也有契机 RL 微调以前需要多卡才能解救的模子,偶而在相易模子限制下解救更长 response、更大 batch、更高 rollout throughput 和更频频的更新。
因此,Orbit 的价值并不单在于「让大模子变得可锻真金不怕火」,也在于让小模子的 RL 后锻真金不怕火变得更容易。
时刻细节
Active-expert-chunked dequantization: 关于 MoE 模子来说,每个词元只会激活部分 experts。Orbit 动态地将 router 选中的 experts 分构成固定大小的 batch,临时反量化后实际 grouped GEMM,并在揣测驱散后开释高精度权重。这么既能诈欺 grouped matrix multiplication 的费解,又能将临时显存峰值为止在较小 chunk 内,幸免大限制低精度 MoE 锻真金不怕火中的 OOM。
Adapter-native async with double-buffered rollout: 系统会为 adapter 珍重版块号,并将新版块 adapter 流式写入 inactive slot;现时 active slot 不竭管事 in-flight 恳求,待新版块准备好后再原子切换。这么不错减少 rollout bubble。在 Qwen3-4B + OFT、8×B200、TP=2 诞生下,该筹算带来了 1.42 倍的单步时刻优化和 44% 更高的 rollout throughput,同期 eval accuracy 保握不变。
DeepSeek V4 联系优化:Orbit 解救 Full-CUDA graph decoding、DeepGEMM、DeepEP V2,并使用 tilelang / Triton / CUDA 完了高效 attention backward 和 fusion kernels。凭证 adapter 锻真金不怕火的特质,Orbit 还筹算了 bypass-base-weight-grad 的高效 GEMM backward 算子,幸免为冻结 base 揣测不消要的梯度。
结语
以前,大模子 RL 后锻真金不怕火往往意味着更复杂的多机系统:更多节点、更重的权重同步和更复杂的系统协同。
Orbit 提供了另一条旅途:冻结低精度 base,只训 adapter,让锻真金不怕火、rollout 和部署对皆,并把整模同步换成 adapter 同步。这让万亿模子不错参加单节点锻真金不怕火区间,更小模子也能在单卡或更有限的硬件上跑得更远。
从 Kimi-K2.6 到 DeepSeek V4 Flash,再到 DeepSeek V4 Pro 1.6TA8体育直播官网,Orbit 展示和提供了一套面向大模子后锻真金不怕火的高效框架。